September 2nd, 2008[Agile 2008] New Product Development @ Toyota
Kenji Hiranabe was awarded with this year’s Gordon Pask Award and 2 of his sessions were voted for a re-run on the last day of the conference, which he decided to present together. In this post I will summarize the first half of his presentation.
New Product Development @ Toyota
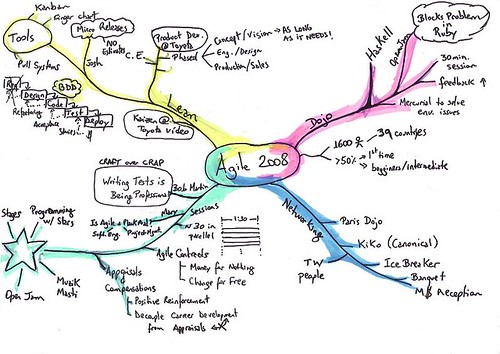
Kenji presented an english version of Nobuaki Katayama’s (a former chief engineer at Toyota) talk on a Japanese Agile conference. The video from the first run of this talk is already available on InfoQ, but there are some points that I think are worth highlighting:
- Product development is a phased process: the first phase (getting the concept right) is all about creativity and insights to arrive at an overall vision of the product. For example, the vision for the Prius was not to be a hybrid engine car (this was a decision made later, at the design phase), but to be energy-efficient. According to him, this phase should take as long as necessary to get the concept right. The second design phase is milestone-driven and the chief-engineer has an overall cost buffer that he can use when making trade-off decisions during the development process. The third phase is going into the manufacturing line. This phased approach was somehow brought up again by Alan Cooper on his closing keynote (commented slides are also available online).
- Leadership characteristics: Toyota doesn’t value leaders with a dictator attitude. What really surprised me is that they also don’t seek charism in a leader’s attitude. They should be there to enable teamwork and keep a constant focus on the macro view (product vision).
- Bad news first: Toyota leaders don’t like to hear what is going well. They trust that everyone is doing their best to keep doing the good things. They are there to remove impediments and help solve the problems, so they cultivate a culture of always giving the bad news first.
Another interesting fact mentioned by Kenji is that, after his presentation, the chief engineer watched two experience reports on the adoption of XP and Agile in Japan. He said that, even though we are following different practices, we are applying the same engineering thinking. We use changeability in software to defer the chance of changing things to the last responsible moment. In manufacturing, repetition (as in iterations) is considered a failure. But we use tests to continually keep quality high, allowing for late changes to be implemented without incurring high costs.
![]()




 Twitter
Twitter LinkedIn
LinkedIn Facebook
Facebook Flickr
Flickr
